一个流量巨大的前端页面面临的浏览器环境是非常复杂的,尤其是移动端页面(Android的碎片化所致)。面对如此多样的浏览器环境,常规的测试是无法完全覆盖的,我们需要一种页面脚本异常监控机制作为补充,保证能够发现前端页面脚本异常的原因。有很多种情况会导致Javascript抛出异常,包括网络失效、语法错误、运行时错误等。我们希望在页面上有异常发生时,能够获得脚本错误的基本信息、文件url、行号。接下来我们探讨几种实现方式。
1 使用window.onError
浏览器提供了全局的onError函数,我们可以使用它搜集页面上的错误
window.onerror = function(message, source, lineno, colno, error) { ... }
其中mesage为异常基本信息,source为发生异常Javascript文件url,lineno为发生错误的行号,我们可以通过error.stack获取异常的堆栈信息。下面是chrome中通过window.onError捕获的错误例子:
message: Uncaught ReferenceError: test is not defined
source: http://test.com/release/attach.js
lineno: 16144
colno: 6
error: ReferenceError: test is not defined
at http://test.com/release/attach.js:16144:6
at HTMLDocument.<anonymous> (http://test.com/release/vendor.js:654:71)
这种方式看似完美,其实有一个致命的问题。有些浏览器为了安全方面的考虑,对于不同域的Javascript文件,通过window.onError无法获取有效的错误信息。比如firefox的错误消息只有Script error,而且无法获得确切的行号,更没有错误堆栈信息:
message: Script error.
source: "http://test.com/release/attach.js
lineno: 0
colno: 0
error: null
为了使得浏览器针对window.onError的跨域保护失效, 我们可以在静态资源服务器或者CDN的HTTP头中加上如下允许跨域提示:
Access-Control-Allow-Origin: *
并在引用Javascript脚本是加上crossorigin属性:
<script crossorigin src=""></script>
完成上述两步后,我们就可以方便的使用window.onError进行全局异常捕获,并获取丰富的异常信息了。但是有时对于第三方的CDN,我们无法添加跨域相关的头信息,下面我们就讨论针这种情况的全局Javascript异常捕获方法。
2 使用AST为所有函数加上try catch
上文中提到了使用window.onError进行浏览器全局异常捕获,但是当我们无法添加跨域相关头信息时,window.onError就失效了。针对这种情况,我们可以对每一个函数添加try catch来捕获函数内的异常,但是一个大型项目的函数太多,对每一个函数都手动添加try catch无疑是一个巨大的工作量。本文我们借助AST(抽象语法树)技术,对源文件进行预处理,对每个函数自动的添加try catch。
语法树是对源代码最精确的表示,通过遍历和操作语法树,我们能够精确的控制源代码。生成JavaScript的AST是一件非常复杂的工作,本文暂时不打算涉及,好在UglifyJS已经有了完整的实现。
比如如下代码:
function test(){
var a = 1;
var b = 2;
console.log(a+b);
}
可以用语法树表示:
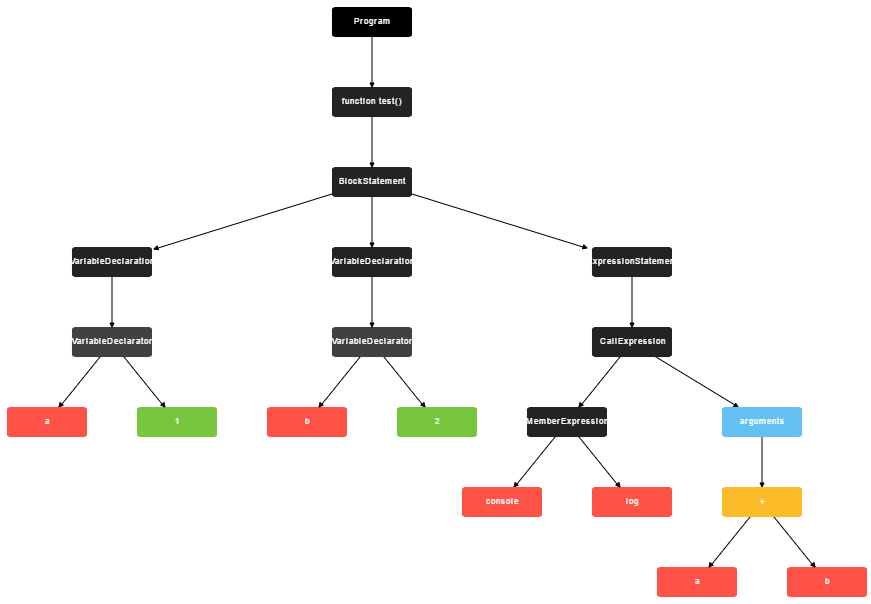
通过使用Uglify提供的操作AST(抽象语法树)的API,我们可以对每个函数添加try catch代码块,并在catch中捕获该函数的一切异常,下面是我的实现(请参考我的github:try-catch-global.js):
var fs = require('fs');
var _ = require('lodash');
var UglifyJS = require('uglify-js');
var isASTFunctionNode = function (node) {
return node instanceof UglifyJS.AST_Defun || node instanceof UglifyJS.AST_Function;
}
var globalFuncTryCatch = function (inputCode, errorHandler) {
if(!_.isFunction(errorHandler)){
throw 'errorHandler should be a valid function';
}
var errorHandlerSource = errorHandler.toString();
var errorHandlerAST = UglifyJS.parse('(' + errorHandlerSource + ')(error);');
var tryCatchAST = UglifyJS.parse('try{}catch(error){}');
var inputAST = UglifyJS.parse(inputCode);
var topFuncScope = [];
//将错误处理函数包裹进入catch中
tryCatchAST.body[0].bcatch.body[0] = errorHandlerAST;
//搜集所有函数
var walker = new UglifyJS.TreeWalker(function (node) {
if (isASTFunctionNode(node)) {
topFuncScope.push(node);
}
});
inputAST.walk(walker);
//对函数进行变换, 添加try catch语句
var transfer = new UglifyJS.TreeTransformer(null,
function (node) {
if (isASTFunctionNode(node) && _.includes(topFuncScope, node)) {
//函数内部代码搜集
var stream = UglifyJS.OutputStream();
for (var i = 0; i < node.body.length; i++) {
node.body[i].print(stream)
}
var innerFuncCode = stream.toString();
//清除try catch中定义的多余语句
tryCatchAST.body[0].body.splice(0, tryCatchAST.body[0].body.length);
//用try catch包裹函数代码
var innerTyrCatchNode = UglifyJS.parse(innerFuncCode, {toplevel: tryCatchAST.body[0]});
//获取函数壳
node.body.splice(0, node.body.length);
//生成有try catch的函数
return UglifyJS.parse(innerTyrCatchNode.print_to_string(), {toplevel: node});
}
});
inputAST.transform(transfer);
var outputCode = inputAST.print_to_string({beautify: true});
return outputCode;
}
module.exports.globalFuncTryCatch = globalFuncTryCatch;
借助于globalFuncTryCatch,我们对每个函数进行自动化地添加try catch语句,并使用自定义的错误处理函数:
globalFuncTryCatch(inputCode, function (error) {
//此处是异常处理代码,可以上报并记录日志
console.log(error);
});
通过将globalFuncTryCatch功能集成到构建工具中,我们就可以对目标Javascript文件进行try catch处理。
综上所述:
当静态资源服务器可以添加Access-Control-Allow-Origin: * 时,我们可以直接使用window.onError进行全局异常捕获;当静态资源服务器不受控制,window.onError失效,我们可以借助AST技术,自动化地对全部目标Javascript函数添加try catch来捕获所有异常。
参考文档
https://blog.sentry.io/2016/01/04/client-javascript-reporting-window-onerror.html
http://lisperator.net/uglifyjs/
https://developer.mozilla.org/en/docs/Web/API/GlobalEventHandlers/onerror
http://rapheal.sinaapp.com/2014/11/06/javascript-error-monitor/