在为solr4.10配置ik-analyzer中文分词器时我参考这篇文章, schema.xml中配置如下:
<fieldType name="text_ik" class="solr.TextField"
sortMissingLast="true" omitNorms="true">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
但是同样的配置在solr4.7上却无法出现了奇怪的现象。首先在solr4.7的Analyse面板中,中文是可以正确分词的。如下图:
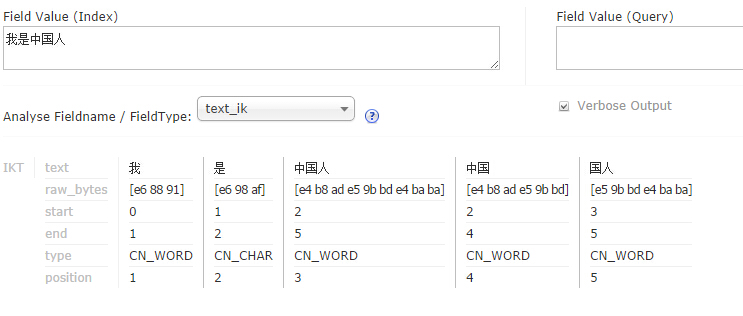
但是使用solr4.7搜索时,却只能搜索出完全匹配的结构。查了网络上的很多资料,才发现问题出在fieldType的autogeneratephrasequeries属性上。
autoGeneratePhraseQueries=true|false (in schema version 1.4 and later this now defaults to false)
这个属性只能用于文本域。如果在查询文本分析时产生了多个词元,比如 Wi-Fi 分词为 Wi 和 Fi ,当 autoGeneratePhraseQueries 被设置为true时,这两个词元就构造了一个词组查询,即“ WiFi ”,所以索引中“ WiFi ”必须相邻才能被查询到;而autoGeneratePhraseQueries被设置成false时,他们只是两个不同的搜索词,它们没有位置上的关系。schema的版本小于1.4时,autoGeneratePhraseQueries默认为true,所以我们需要将autoGeneratePhraseQueries设置为false。
所以solr4.7下正确的配置应该是
<fieldType name="text_ik" class="solr.TextField" sortMissingLast="true" omitNorms="true" autoGeneratePhraseQueries="false">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>