Web应用加载性能的优化, 一直围绕着对静态资源地缓存。实现手段也从最初的浏览器和服务器缓存协商,到HTML5离线缓存机制和使用localstorage缓存js和css。Google提出PWA(Progress Web Apps)的方案后,更证明了缓存的价值。
PWA被Google称为下一代web应用技术,对比传统的Web应用技术,其主要有如下特点:借助于Service Worker提供的可编程式缓存,实现更可靠地(不同网络状态下)、速度更快地用户体验;借助于Web App Manifest将Web应用像原生应用一样安装到系统主屏。由于各个浏览器对PWA的兼容实现进度不一,我们暂时无法大规模实施PWA方案;真正应该引起我们注意的是其背后的技术方案:Service Worker。本文我们借助于Service Worker对PWA进行部分实践,将静态资源的缓存技术提升一个维度。
HTML5标准中引入了web worker,它是运行在后台的JavaScript,独立于其他脚本,不会影响页面的性能。Service Worker就是Web Worker的一种实现,充当Web应用程序的本地代理服务器;在特定路径注册Service Worker后,我们可以拦截并处理该路径下的所有网络请求;本文中,我们就是借助于这种代理机制,实现对web页面核心资源可编程式缓存。
1. Service Worker基础知识
1.1 基本用法
(1) 注册Service Worker
在支持Service Worker的浏览器中,我们可以通过register方法,在当前域名的某个路径下注册一个service worker脚本:
navigator.serviceWorker.register('your_service_worker.js',{scope: 'your-path-name'}).then(function (registration) {
console.log('[SW]: Registration succeeded.');
}).catch(function (error) {
console.log('[SW]: Registration failed with.' + error);
});
(2) 注销Service Worker
同样地,我们可以通过getRegistration获取已经注册的Service Worker,并通过unregister取消已经注册的Service Worker脚本。
navigator.serviceWorker.getRegistration('your_service_worker.js',{scope: 'your-path-name'}).then(function (registration) {
if (registration && registration.unregister) {
registration.unregister().then(function (isUnRegistered) {
if (isUnRegistered) {
console.log('[SW]: UnRegistration succeeded.');
} else {
console.log('[SW]: UnRegistration failed.');
}
});
}
).catch(function (error) {
console.log('[SW]: UnRegistration failed with. ' + error);
});
(3) Service Worker脚本
通过register方法,注册Service Worker脚本后,就可以通过监听Service Worker提供的生命周期方法来实现我们自己的业务逻辑了。如下的代码实现了一个简单的功能:监听Service Worker的install事件、activate事件和fetch事件,打印出所有的网络请求url。
self.addEventListener('install', event => {
console.log('sw installing…');
});
self.addEventListener('activate', event => {
console.log('sw now ready!');
});
self.addEventListener('fetch', event => {
console.log(event.request.url);
return;
});
2.2 生命周期
作为一个事件驱动的本地代理服务,Service Worker有着复杂的生命周期。如下图所示
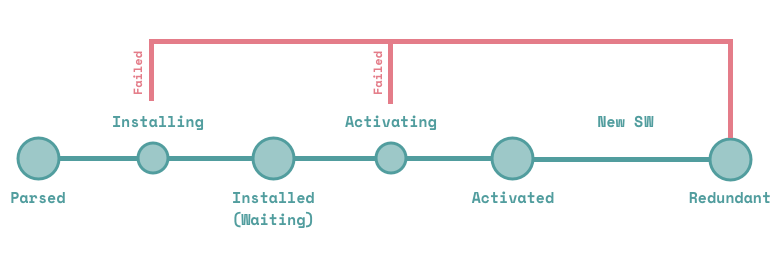
我们主要关注Service Worker脚本的下载、解析、安装、激活、废弃
(1) 下载并解析
在注册Service Worker后,浏览器首先从指定路径下载并解析工作线程脚本。需要注意的是,出于安全考量,工作线程脚本只能由HTTPS承载;为了方便调试,使用localhost域名可以本地在调试工作线程脚本。
(2) 安装
成功下载并正确解析后,浏览器开始安装工作线程脚本。如果安装成功,则Service Worker会触发install事件并进入等待激活(Activating)状态,安装失败则Service Worker进入废弃(Redundant)状态。
(3) 激活
处于等待激活的Service Worker,会在以下之一的情况下,会被触发激活 - 当前已无其他处于激活状态的Service Worker - 通过调用self.skipWaiting()强制激活 - 此前处于激活状态的Service Worker已经过期(通过刷新页面可以使旧的Service Worker过期)
激活成功后,Service Worker会触发active事件,并开始事实上接管页面的所有网络请求(fetch)。激活失败则Service Worker会进入废弃(Redundant)状态。
(4) 废弃(Redundant)
Service Worker可能以下之一的原因而被废弃(redundant) - installing 事件失败 - activating 事件失败 - 被新的Service Worker取代
Service Worker生命周期的任何过程出现错误都会导致其进入废弃(Redundant)状态,而处于废弃(Redundant)状态的Service Worker,对页面没有控制权,这样就保证了错误Service Worker不会干扰页面的正常加载流程。
2.3 主要依赖
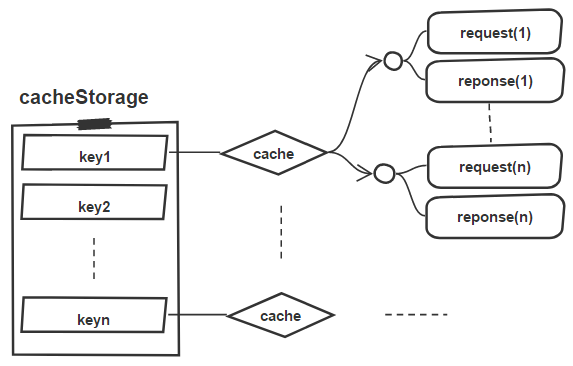
Service Worker作为现代浏览器的高级特性,依赖于fetch、promise、CacheStorage、cache、等浏览器基础能力。对每一个前端开发来说,fetch和promise应该都比较熟悉了。而Cache提供了Request / Response对象对的存储机制。而CacheStorage则提供了存储Cache对象的机制。
3. 静态资源全缓存最佳实践
PWA(Progress Web Apps)倡导离线可用的WEB应用,缓存包括主资源HTML文档在内的所有资源;这就使得WEB应用的程序入口由HTML文档变成Service Worker本身,我们也因此失去了对web应用的控制权;而且不同浏览器对Service Worker更新机制的实现并不一致,这可能导致我们陷入WEB应用无法更新或者更新不及时的危险之中。本文中我们探讨一种更具有可行性的方案:依然把HTML文档作为Web应用的入口,考虑只把Service Worker作为可编程的缓存,使用它来缓存包括css、js等在内的页面核心静态资源。
使用Service Worker缓存资源的一般思路是:
监听install事件提前缓存静态资源
监听fetch事件,拦截网络请求并返回cache中已缓存的资源
如下所示:
var CACHE_NAME = 'my-site-cache-v1';
var urlsToCache = [
'/',
'/styles/main.css',
'/script/main.js'
];
//service worker安装成功后开始缓存所需的资源
self.addEventListener('install', function(event) {
// Perform install steps
event.waitUntil(
caches.open(CACHE_NAME)
.then(function(cache) {
console.log('Opened cache');
return cache.addAll(urlsToCache);
})
);
});
//监听浏览器的所有fetch请求,对已经缓存的资源使用本地缓存回复
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
//该fetch请求已经缓存
if (response) {
return response;
}
return fetch(event.request);
}
)
);
});
上述简单的示例描述了Service Worker的基本用法,但依然有不少问题,下面我们详细的讨论如何借助Service Worker实现一套安全、可靠的缓存系统。
3.1 版本控制
使用Service Worker作为缓存系统的一个核心优势之一,就是它的细粒度可控性;但这意味着我们需要自己处理缓存的版本管理问题。cacheStorage为此提供了简单的API,方便我们遍历所有的cache、找出过期的cache并删除:
function deleteObsoleteCache() {
return caches.keys().then(function (keys) {
var all = keys.map(function (key) {
if (key.indexOf(CACHE_PREFIX) !== -1 && key.indexOf(CACHE_VERSION) === -1){
console.log('[SW]: Delete cache:' + key);
return caches.delete(key);
}
});
return Promise.all(all);
});
}
上述代码中,我们通过使用CACHE_PREFIX和CACHE_VERSION来标志web应用的缓存版本。其中CACHE_PREFIX是应用的cache前缀,CACHE_VERSION是本次cache的版本号,CACHE_PREFIX+CACHE_VERSION就构成了本次cache的key。我们遍历cacheStorage中所有的key,并找出该web应用已经过期的key,然后从cacheStorage中删除对应的cache。
3.3 白名单控制
默认情况下,Service Worker会代理页面中的所有网络请求;而比较安全的做法是通过通过白名单控制需要代理的网络请求url,并对其他请求使用浏览器默认行为。
//资源白名单,一般通过构建工具(webpack)生成
var allAssets = [
'//your.cdn.com/app.css',
'//your.cdn.com/common.js',
'//your.cdn.com/index.js'
];
//白名单匹配策略
function matchAssets(requestUrl) {
var urlObj = new URL(requestUrl);
var noProtocolUrl = urlObj.href.substr(urlObj.protocol.length);
if (allAssets.indexOf(noProtocolUrl) !== -1) {
return true;
}
return false;
}
//监听fetch事件,并只代理白名单中的GET网络请求
self.addEventListener('fetch', function (event) {
try{
var requestUrl = event.request.url;
var isGET = event.request.method === 'GET';
var assetMatches = matchAssets(requestUrl);
if (!assetMatches || !isGET) {
return;
}
var resource = cacheFirstResponse(event);
event.respondWith(resource);
}catch(ex){
console.error('[SW]: handle fetch event error, fallback');
return;
}
});
一般情况下,我们会在构建阶段通过构建工具生成资源白名单;上述代码中,我们了实现白名单匹配策略;然后使用Service Worker监听fetch事件,有选择地只对白名单中的网络请求进行处理。
3.4 安全性问题规避
(1)跨域请求支持
Service Worker可以拦截它管辖范围内的所有请求,跨域资源也不例外。但是浏览器默认对跨域资源发起的是ncors请求,得到的response是opaque的,这导致我们无法判断跨域请求是否成功,以便进行缓存。
对于跨域请求,我们需要修改fetch请求头,添加mode:'cros'标记。
//初始化请求参数,添加跨域头
var fetchInitParam = {
mode: 'cors'
};
function fetchCros(request) {
//add cros header
return fetch(request.url, fetchInitParam);
}
(2)避免缓存错误的结果
由于更新机制的问题,如果Service Worker缓存了错误的结果,将会对web应用造成灾难性的后果。我们必须小心翼翼的检查网络返回是否准确。一种常见的做法是只缓存满足如下条件的结果:
1. 响应状态码为200;避免缓存304、404、50x等常见的结果
2. 响应类型为basic或者cors;即只缓存同源、或者正确地跨域请求结果;避免缓存错误的响应(error)和不正确的跨域请求响应(opaque)
如下代码所示:
fetchCros(request).then(function (response) {
//严格判断缓存是否成功
if (response.status === 200 && (response.type === 'basic' || response.type === 'cors')) {
console.log('[SW]: URL [' + request.url + '] from network');
cache.put(event.request, response.clone());
} else {
console.log('[SW]: URL [' + event.request.url + '] wrong response: [' + response.status + '] ' + response.type);
}
return response;
});
(3) http缓存穿透
需要注意的是在Service Worker脚本中,使用fetch发起网络请求时,依然会使用浏览器和服务端的缓存协商机制. 而在使用Service Worker缓存js、css等资源文件时,我们尤其需要注意,因为这些文件都是放在CDN中的,往往都使用了强缓存策略。 这样就会导致我们对资源文件的fetch请求,大部分会返回304状态。为了避免缓存错误的结果,我们只能放弃对该资源的缓存,从而导致Service Worker工作机制失效。往往通过对请求添加时间戳,就可以绕过浏览器的默认缓存协商机制:
function applyCacheBust(assetURL) {
var hasQuery = assetURL.indexOf('?') !== -1;
return assetURL + (hasQuery ? '&' : '?') + '__bust=' + encodeURIComponent(CACHE_TAG) + '-' + new Date().getTime();
}
除了上述几点之外,我们还需要注意避免在install阶段缓存过多资源,以防止install失败;而且需要注意在fetch事件处理出现异常时,跳过Service Worker,而使用浏览器默认请求,以降低Service Worker对Web应用可用性的影响;当然,在极端情况下,我们还需要提供快速取消Service Worker注册的机制。
https://developers.google.com/web/progressive-web-apps/
https://developers.google.com/web/fundamentals/engage-and-retain/web-app-manifest/
https://developer.mozilla.org/zh-CN/docs/Web/API/Service_Worker_API
https://bitsofco.de/the-service-worker-lifecycle/
https://github.com/ruanyf/articles/blob/master/dev/web/serviceworker.md
https://github.com/pazguille/offline-first
https://github.com/NekR/offline-plugin
https://github.com/GoogleChrome/sw-precache
https://jakearchibald.com/2016/caching-best-practices/
https://github.com/lyzadanger/serviceworker-example/blob/master/03-versioning/serviceWorker.js
https://googlechrome.github.io/sw-toolbox/usage.html
https://www.smashingmagazine.com/2016/02/making-a-service-worker/
https://x5.tencent.com/tbs/guide/serviceworker.html
https://developer.mozilla.org/en-US/docs/Web/API/Response/type