开始之前,先来个段子,博君一笑:
虽然go成为了世界上最并发的语言,但是, 这并不妨碍php成为世界上最好的语言,也不妨碍java成为世界上最有模式的语言,更不会妨碍c++成为21 天就能学会了的语言...但是JavaScript终将统治世界,而V8将成为世界的基石!
1. node内存分配基础
在V8中所有的JavaScript对象都是通过堆来分配的。为了提高垃圾回收的效率,V8将堆分为新生代和老生代两个部分,其中新生代为存活时间较短的对象(需要经常进行垃圾回收),而老生代为存活时间较长的对象(垃圾回收的频率较低)。
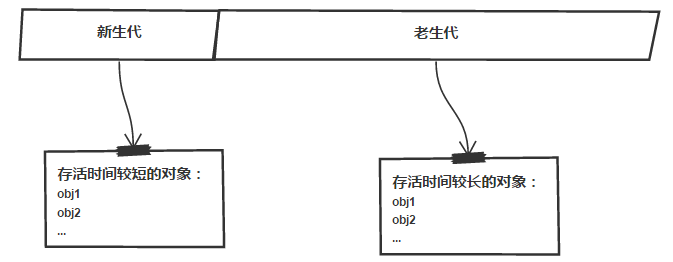
新生代和老生代的默认内存限制在启动的时候就确定了,没办法根据应用使用内存情况自动扩充,当应用分配过多内存时,就会引起OOM(Out Of Memory,内存溢出)进程错误。64位系统和32位系统的内存限制不同,分别如下:
| 类型 | 64位系统 | 32位系统 |
|---|---|---|
| 新生代 | 32MB x 2 | 16MB x 2 |
| 老生代 | 1400MB | 700MB |
| 实际可用内存 | 1432MB | 716MB |
在node启动时,通过--max-new-space-size和--max-old-space-size可分别设置新生代和老生代的默认内存限制。V8为什么要对内存做如此限制呢?最终的原因还是V8的垃圾回收机制所限制的,在较大的内存上进行垃圾回收是很耗时地。下面我们就来了解一下V8的垃圾回收机制。
2. node垃圾回收原理
2.1 常用垃圾回收基本算法
垃圾回收机制有多种,但最常用的就是以下几种:
| 类型 | 方法 | 是否停止程序 |
|---|---|---|
| 引用计数(Reference Counting) | 每个对象配置一个计数器即可,每当引用它的对象被删除时,就将其引用数减1,当其引用计数为0时,即可清除 | 否 |
| 标记-清除(Mark-Sweep) | 标记阶段标记活对象,清除阶段清除未被标记的对象 | 是 |
| 停止-复制(Stop-Copy) | 内存分为两块,并将正在使用的内存中的存活对象复制到未被使用的内存块中,之后,清除正在使用的内存块中的所有对象,交换两个内存的角色 | 是 |
| 标记-压缩(Mark-Compact) | 对所有可达对象做一次标记,将所有的存活对象压缩到内存的一端,以减少内存碎片 | 是 |
| 增量算法(Incremental Collecting) | 每次,垃圾收集线程只收集一小片区域的内存空间,接着切换到应用程序线程。依次反复,直到垃圾收集完成。 | 否 |
2.2 V8的分代垃圾回收
上面提到过,V8将内存分为新生代和老生代,新生代中对象存活时间较短,老生代中对象存活时间较长。为了最大程度的提升垃圾回收效率,V8使用了一种综合性的方法,其在新生代和老生代中分别使用上文提到的不同的基本垃圾回收算法。
[1] 新生代垃圾回收算法Scavenge
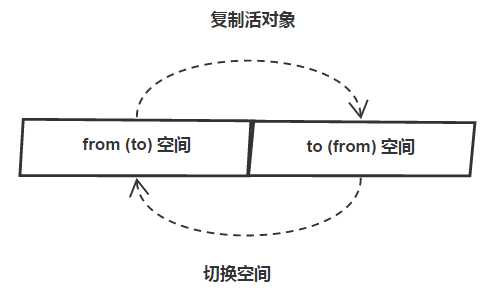
在新生代中,由于内存较小(64位系统为64MB)且存活对象较少,V8采取了一种以空间换时间的方案,即停止-复制算法 (Stop-Copy)。它将新生代分为两个半区域(semi-space),分别称为from空间和to空间。一次垃圾回收分为两步:
(1) 将from空间中的活对象复制到to空间
(2) 切换from和to空间
V8将新生代中的一次垃圾回收过程,称为Scavenge。
[2] 老生代垃圾回收算法
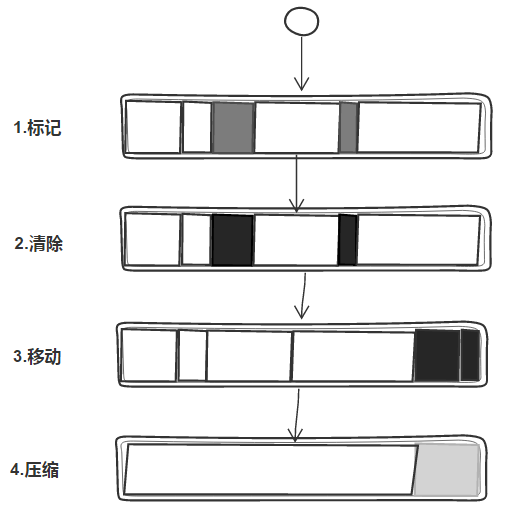
老生代的内存空间较大且存活对象较多,因此其垃圾回收算法也就没有新生代那么简单了。为此V8使用了标记-清除算法 (Mark-Sweep)进行垃圾回收,并使用标记-压缩算法 (Mark-Compact)整理内存碎片,提高内存的利用率。老生代的垃圾回收算法步骤如下:
(1).对老生代进行第一遍扫描,标记存活的对象
(2).对老生代进行第二次扫描,清除未被标记的对象
(3).将存活对象往内存的一端移动
(4).清除掉存活对象边界外的内存
从上面的表格可以看出,停止-复制(Stop-Copy)、标记-清除(Mark-Sweep)和标记-压缩(Mark-Compact)都需要停止应用逻辑,我们将之称为stop-the-world。但因为新生代内存较小且存活对象较少,即便stop-the-world,对应用的性能影响也不大;而老生代的内存很大,stop-the-world就不能接受了,为此V8引入了增量标记。增量标记使得应用逻辑和垃圾回收交替运行,减少了垃圾回收对应用逻辑的干扰。
2.3 分代垃圾回收的代价
在讨论新生代中的垃圾回收算法Scavenge时,我们忽略了许多细节。
真的仅仅扫描新生代的内存空间,就能确定新生代的活动对象吗?
当然不是,老生代的对象也可能引用新生代的对象啊。如果每次运行Scavenge算法时,都要扫描老生代空间的话,这种操作带来的性能损耗就完全抵消了分代式垃圾回收所带来的性能提升。为此V8使用写屏障技术解决了这个问题:
V8使用一个列表(我们称之为CrossRefList)记录所有老生代对象指向新生代的情况,当有老生代中的对象出现指向新生代对象的指针时,便记录下来这样的跨区指向。由于这种记录行为总是发生在写操作时,因此被称为写屏障。
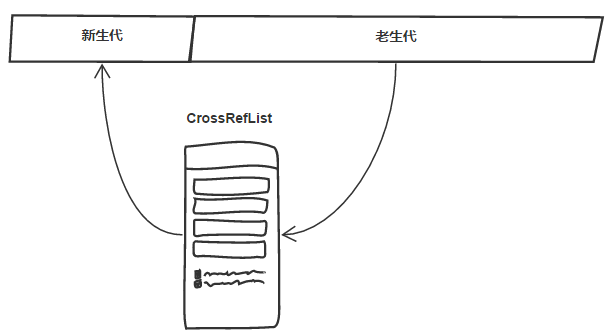
每个写操作都要经历这样一关,性能上必然有损失,这是分代垃圾回收的代价之一。通过使用写屏障技术,我们在对新生代进行垃圾回收时,只需要扫描新生代From空间和CrossRefList列表就可以确定活动对象了。
3.垃圾回收监控
理解了垃圾回收的基本原理以后,我们来看一看如何监控node的垃圾回收情况。查看垃圾回收方式的最方便的方法是通过在启动时使用--trace-gc参数:
node --trace-gc app.js
1254 ms: Scavenge 413.1 (460.9) -> 413.1 (460.9) MB, 0.5
/ 0 ms (+ 3.0 ms in 14 steps since last GC)
1258 ms: Mark-sweep 413.5 (461.9) -> 412.6 (461.9) MB, 1.0
/ 0 ms (+ 255.0 ms in 2050 steps since start of marking, biggest step 1.0 ms)
[GC interrupt] [GC in old space requested]
从控制台日志中可以轻易的看出node的垃圾回收动作,包括新生代垃圾回收(Scavenge)和老生代垃圾回收(Mark-sweep)。
而一种更加程序化的方式是使用memwatch-next模块,该模块在node每一次进行全量垃圾(full-gc,包括标记-清除和标记-压缩)回收时触发相应的事件:
var memwatch = require('memwatch-next');
memwatch.on('stats', function(stats) {
console.log(stats);
});
上述代码监控每一次全量垃圾回收动作,并打印出相应垃圾回收统计信息:
{
"num_full_gc": 8, //目前为止进行全量GC的次数
"num_inc_gc": 18, //目前为止进行增量GC的次数
"heap_compactions": 8, //目前为止进行的内存压缩的次数
"usage_trend": 0, //内存增长趋势,如果一直大于0,则可能有内存泄露
"estimated_base": 2592568,
"current_base": 2592568,
"min": 2499912,
"max": 2592568
}
4.内存泄露定位
使用上文提到的垃圾回收监控方法,我们可以知道程序是否有内存泄露,那么具体在什么地方有内存泄露呢?我们需要借助于新的工具。node-heapdump提供了v8的堆内存快照抓取工具。
4.1 抓取对内存镜像
我们可以在程序中直接通过它提供的函数抓取内存快照:
var heapdump = require('heapdump');
heapdump.writeSnapshot('/tmp/' + Date.now() + '.heapsnapshot');
在linux下,我们还可以通过向node进程发送信号来抓取内存快照:
kill -USR2 pid
有了内存快照后,我们就可以借助chrome的Profile工具,具体的分析内存泄露发生在什么地方了。
4.2 三次快照法
利用chrome的Profile工具分析内存泄露的经典方法是三次快照法,我们需要首选准备3个内存快照文件:
(1) 第一次获取正常情况下内存快照
(2) 第二次获取发生内存泄露时的内存快照
(3) 第三次获取继续发生内存泄露时的内存快照
三次快照要求第一次必须在没有出现内存泄露时,是为了过滤一些无用的信息,使得分析结果可读性更强。
5.常见的内存泄露case
了解了node内存的基本原理后,我们一起来看一看常见的内存泄露case。
5.1 使用对象作为缓存
使用javascript键值对作为缓存,我们几乎必然要承担内存泄露的风险,因为严格意义的缓存有完善的过期策略,而普通的javascript对象显然不具备这个功能:
var cache = {};
function getFromCache(key){
if(cache[key]){
return cache[key];
}else{
cache[key] = new CacheItem();
return cache[key];
}
}
上述cache里缓存的item永远得不到释放,尽管没有任何引用。那么如果我们确实需要使用缓存呢?有两种方案:
(1) 使用外部缓存服务,比如memcahe
(2) 使用es6的WeakMap作为程序内缓存数据结构
WeakMap是ES6标准中新引入的一种类似字典的数据结构,和普通字典数据结构不同的是,当WeakMap中key没有其他引用,并且value也没有除key之外的引用时,value可以被垃圾回收,这是一种程序内缓存的理想选择。
6.堆外内存
在node中,我们不可避免的需要操作大内存,而堆内内存大小的限制显然无法满足我们的要求。为此,node通过内置的全局Buffer模块提供堆外的内存使用方法。Buffer是一个C++与Javascript结合的模块,其内存分配策略,也非常值得我们研究。我们知道大部分Javascript对象所使用的内存都是很小的,如果每一次都向操作系统申请,就必须频繁地进行系统调用;为了解决这个问题,node使用C++层面申请一大块内存,然后按需分配给Javascript的策略;也就是*nix系统常用的slab内存分配策略,这是一种典型的对时间和空间的折衷算法(time/space trade-off)。
slab是一块提前申请好地固定大小的内存,一个slab有三种状态:full、partial、empty。node层面提供了一个SlowBuffer类,封装C++的api,用于申请真实的物理内存,可以简单地将一个slab理解为一个SlowBuffer对象。node中维护着一个名为pool的指针,它指向当前slab(SlowBuffer对象)。向系统申请slab的过程可用如下伪代码表示:
var pool;
function allocateSlab(){
pool = new SlowBuffer();
pool.used = 0;
}
6.1 小内存(<4kB)的分配
一个slab的大小为8KB(Buffer.poolSize),node中通过Buffer.poolSize定义。当我们需要创建一个长度小于4kB的Buffer对象时,会首先判断当前slab的剩余空间是否足够,如果剩余空间足够,则在当前slab上为Buffer对象分配内存,否则创建一个新的slab块,并在新的slab上为Buffer对象分配内存。
if(!pool || pool.lengh - pool.used < this.length){
allocateSlab(); //向系统申请新的slab
allocateBuffer(); //给buffer对象分配内存
}else{
allocateBuffer(); //给buffer对象分配内存
}
从当前slab上为Buffer分配内存的算法也很容易理解,只需要将Buffer指向slab的某段内存,并调整pool的length和used等属性:
function allocateBuffer(){
this.parent = pool; //buffer的parent属性指向当前slab
this.offset = pool.used; //buffer的offset属性指向当前slab可用内存段的开始位置
pool.used += this.length; //调整buffer的已使用空间
}
由此可见,一个slab(SlowBuffer对象)可供多个小内存的Buffer共用:
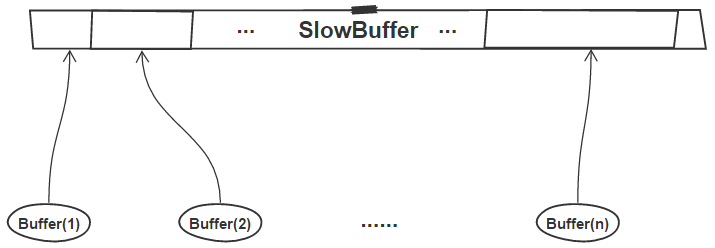
在写本文时,node官方已经不建议使用new Buffer()创建buffer对象了,官方提供了更新的Buffer.alloc()和Buffer.allocUnsafe()。其中Buffer.alloc()在创建Buffer对象时会对内存进行初始化,并且不会使用slab策略;而Buffer.allocUnsafe()则是使用slab算法分配一块未初始化的内存,因此其性能要比Buffer.alloc()高很多。因此我们应该使用Buffer.allocUnsafe()替换来的new Buffer()。
6.2 大内存(>4kB)的分配
对于大于4KB的Buffer对象,其大小甚至可能超过一个slab的大小,系统就无法使用固定大小的slab分配算法了。值得注意的是,node对单个Buffer大小是有上限的(buffer.kMaxLength),在32系统上其上限接近1GB(230-1),而在64位系统上其上限则接近2GB(231-1)。
6.3 slab算法的代价
鱼与熊掌不可兼得,上文中提到slab算法一种时间和空间的折衷算法。为了提高内存的分配速度,该算法可能导致内存碎片:当一个slab上的剩余空间不足于容纳新申请的Buffer的大小,或者新申请Buffer大于等于4kb(Buffer.poolSize)时,就需要创建新的slab,原来slab上剩余的空间就浪费了。我们写个小程序证明一下我们的猜想:
function testBufferSlab(size){
var itt = 10000;
var store = [];
var rss = process.memoryUsage().rss;
var tmpMem;
for(var i =0 ;i < itt; i++){
store.push(new Buffer(1));
tmp = Buffer(size);
if(i/1000){
global.gc();
}
}
var nr = process.memoryUsage().rss
console.log((((nr - rss) / 1024 / 1024).toFixed(2)));
}
上述程序,在一万次循环中申请了一个1字节的全局缓存,并申请了size大小的临时缓存(其引用会在循环中被垃圾回收)。我们分别给testBufferSlab传递两个特殊的参数:Buffer.poolSize和Buffer.poolSize/2-1,并观察结果时,奇怪的现象发生了(申请较大的Buffer时竟然消耗更少的内存):
testBufferSlab(Buffer.poolSize);
node --expose-gc test.js
output: 5.2
testBufferSlab(Buffer.poolSize/2-1);
node --expose-gc test.js
output: 54.78
究其原因就是:当新申请的Buffer的小于4Kb时(Buffer.poolSize/2),会使用slab算法,即便当前Buffer块已经没有引用了,只要其对应slab上还有其他Buffer指向时,整个slab内存就无法释放,这样就会造成内存碎片。
参考文章:
https://www.ibm.com/developerworks/cn/java/j-lo-JVMGarbageCollection/
https://www.zhihu.com/question/20018826
https://github.com/caoxudong/oracle_jrockit_the_definitive_guide/blob/master/chap3/3.3.md
http://newhtml.net/v8-garbage-collection/
http://taobaofed.org/blog/2016/04/15/how-to-find-memory-leak/
https://developer.mozilla.org/en/docs/Web/JavaScript/Reference/Global_Objects/WeakMap
https://github.com/promises-aplus/promises-spec/issues/179
https://www.ibm.com/developerworks/cn/linux/l-linux-slab-allocator/
https://nodejs.org/api/buffer.html
http://stackoverflow.com/questions/14009048/what-makes-node-js-slowbuffers-slow